

Next: 2.3.4 display
Up: 2.3 Usage
Previous: 2.3.2 generate
The cluster program reads an unclustered dataset from standard input,
such as one created by the generate program. It then runs the specified
clustering algorithm on this dataset, and outputs the resultant clustered dataset
to standard output. The representatives of clusters are also output, and the
annotations of the dataset points are preserved.
The algorithms themselves will be detailed later.
Usage:
cluster [OPTIONS]
- -help
- Outputs a brief usage message.
- -debug
- Output debugging information.
- -algorithm algorithmname [k]
- Specifies
the clustering algorithm to use, and optionally a suggestion for the number
of clusters (
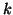 ) for those algorithms which need or benefit from it. algorithm_name
defaults to ``kmeans'', defaults to 4.
) for those algorithms which need or benefit from it. algorithm_name
defaults to ``kmeans'', defaults to 4.
Available algorithms:
- kmeans
- The standard -MEANS algorithm, Section 3.3.
- tb
- The Teitz-Bart -MEDOIDS heuristic, Section 3.4.
- ech
- The ECH variant of the TB -MEDOIDS heuristic, Section
3.5.
- random
- Random clustering (equal sized clusters), Section 3.2.
- cheat
- Cheating clustering, using the annotation, Section 3.1.3.
- ascending
- Puts each point into its own cluster, Section 3.1.2.
- single
- Puts all points into a single cluster, Section 3.1.1.
Next: 2.3.4 display
Up: 2.3 Usage
Previous: 2.3.2 generate
Kevin Pulo
2000-08-23