First In First Out (FIFO)
-
In this rather simple minded strategy pages are brought in as required,
and if there is no free frame, the page chosen to be removed is the one
that has been in a frame for the longest.
-
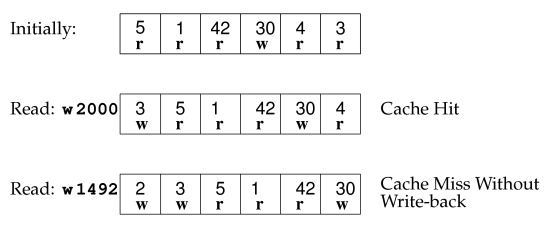
Consider the example shown below. Suppose that at some point the cache
contains the pages 5, 1, 42, 30, 4 and 3, where page 5 was read in most
recently, and page 3 has been present in the cache the longest. The
frame containing page 30 is the only dirty frame. The page size
is 512 bytes and there are 6 frames in the cache, so this cache would
have initially been specified by the string "F 512 6".
-
Suppose now that the line w 2000 is read in by the main
program. This address is located in page 3. We search the cache and
discover that page 3 is already present a frame of the cache. Thus,
this operation is a cache hit. However, since we are performing a
write operation, the frame containing page 3 is now dirty, and so we
mark it as being dirty.
-
Suppose now that the line w 1492 is read in by the main
program. This address is located in page 2. We search the cache and
discover that page 2 is not present in any of the frames of the cache.
Thus, this operation is a cache miss. The FIFO algorithm must now
decide which frame is to be removed to make way for the new page (page
2). The FIFO algorithm chooses the page which has been in a frame for
the longest, which is page 3. So page 3 is removed from the cache.
But page 3 was marked as being dirty, so that means that a write-back
is required. Thus, the operation w 1492 is not only a cache
miss, but it is in fact a cache miss with write-back. After the frame
containing page 3 has been removed, page 2 is read into a frame and
placed at the front of the list (since it is now the most recently read
page). Since we are performing a write operation, the frame containing
page 2 is immediately marked as being dirty.

Least Recently Used (LRU)
-
The LRU paging algorithm is similar to the FIFO paging algorithm,
except that when a cache hit is encountered, the corresponding frame is
moved to the front of the list. In this way, the front of the list
always contains the frame which was most recently used, and the back of
the list contains the frame which was least recently used. Now when a
page must be removed, the frame at the back of the list is removed -
which is the frame which was least recently used (hence the name of the
algorithm).
-
Consider the example shown below. It is the same as the example shown
above, in that it has the same initial state, and the operations
performed are the same. Again, the page size
is 512 bytes and there are 6 frames in the cache, so this cache would
have initially been specified by the string "L 512 6".
-
Consider the first operation of writing to address 2000, located in
page 3. We again search the cache and find page 3 present in a frame.
Thus, we have a cache hit. However, this time the frame containing
page 3 is moved to the front of the list. It is also marked as being
dirty, the same as before.
-
Now consider the second operation of writing to address 1492, located
in page 2. We again search the cache and find page 2 not present.
Thus, we have a cache miss. Again, the LRU paging algorithm chooses to
remove the frame from the back of the list. In this case, the frame
contains page 4 and is clean. Thus when it is removed, no write-back
is needed, and this is a cache miss without write-back. As before,
page 2 is loaded into a frame at the front of the list and marked as
dirty.
-
Notice that in this case, we obtained a cache miss without write-back,
whereas the same situation applied to the FIFO paging algorithm
resulting in a cache miss with write-back.
Pipelined LRU
-
The Pipelined LRU paging algorithm is similar to the LRU paging algorithm,
except that it deliberately and explicitly attempts to avoid removing a
frame which contains a page that will be required again in the near
future.
-
For example, consider the above example shown for the LRU paging
algorithm. Now suppose that after doing the w 1492 operation,
the very next operation was r 2156. The address 2156 is in
page 4, but page 4 was just removed by the LRU paging algorithm! If we
had some way of knowing in advance that page 4 was going to be used again soon,
then we could have chosen to remove a different frame, such as the one
containing page 30.
-
In fact, it somewhat is possible to know the upcoming operations in
advance. Modern CPUs have a feature known as pipelining.
In loose terms, this is where more than one instruction is in the
process of being executed at any given time. This means that we can
search the list of upcoming instructions to see what addresses will be
used in the near future, and we can then attempt to avoid removing the
pages containing those addresses (if possible). This is what the
Pipelined LRU paging algorithm does - it "looks ahead" in the sequence
of read and write operations to see which pages are used in the near
future, and then attempts to avoid removing those pages. (A note to
any hardware purists - yes, I know that it's generally not possible to
"search" the pipelined instructions as I have described above. But
this is an assignment on programming, not hardware, and so this problem
is simple ignored.)
-
Earlier in the specification it was noted that two additional integers
were specified for the Pipelined LRU paging algorithm, being the
lookahead value and the number of frames to check. The
lookahead value (referred to as lookahead) is the number of read and write operations which should
be checked in advance. The number of frames to check (referred to as
check_frames) is the number of
frames from the back of the list which should be checked for possible
removal candidates.
-
When a frame must be found for removal, the last
check_frames frames in the cache should be examined, and the
first one found which is not required by the next lookahead
operations is the frame which should be removed.
-
If all of the frames
examined are required by the next lookahead operations, then
the frame to be removed is the one examined which is required latest by
the lookahead list.
-
At this point, you might like to have a look at the Pipelined LRU
examples below.
-
If the value of check_frames is larger than the number of
frames, then all of the frames should be searched.
-
You will need to keep a list of "pipelined" read/write operations,
which is usually called the lookahead list. Initially this
list is empty, but when a read/write operation is requested, it should
push that operation onto the front of the list. When there are
lookahead operations in the list, pushing an operation
should also cause an operation to be popped from the back of the list and
processed. This means that the list will only ever have at most
lookahead operations on it. (Note that you don't have to
store the lookahead list using a list data structure, but it's usually
easiest to think of it as a list.)
-
During the initial stage when there are less than lookahead
operations on the list, then no operations should be processed. This
means that there should be no cache hits, misses without writeback or
misses with writeback recorded, and during this stage the output of the
main.cc main program should be "0 0 0".
-
When there is no more input, the main.cc main program will call the
flush() method on your Cache object. This indicates to the
Cache object that there are no more read/write operations. At this
point, the Cache object should process each of the operations in the
lookahead list in turn as per normal, until all the operations have
been processed and the list is empty. Despite the lookahead list
containing less than lookahead operations, it should still
be checked in the normal way, as described above.
-
You might think about storing all of the read/write operations in a
large list, and then processing all of them when the flush()
method is called. You shouldn't do this for two reasons:
- The list of read/write operations may be very large, and
- You have to have the correct values of the number of cache hits, misses without write-back and misses with write-back throughout the course of the simulation, not just at the end of the simulation.
Pipelined LRU - Example 1
-
Consider the Pipelined LRU paging algorithm corresponding
to the input string of P 512 6 3 4, ie. the value of
lookahead is 3 and the value of check_frames is
4.
-
The initial state of the cache is

(ie. the state of the cache after the initial operation in the example given above for the LRU paging algorithm).
-
Since the value of lookahead is
3, we need to know the current read/write operation along with the next
3 operations. Suppose these are:
- w 1492 (page 2)
- w 50 (page 0)
- w 15400 (page 30)
- r 2200 (page 4)
-
So the current operation being performed is a write to address 1492,
which is page 2. Page 2 is not in the cache (ie. a cache miss), so we
need to find a frame to remove.
-
We start with the last frame in the
cache, which contains page 4. However, page 4 appears in the lookahead
list of operations (the r 2200 operation), so we don't remove
this frame.
-
We now look at the next frame,
which contains page 30. Again, page 30 appears in the lookahead list
of operations (the w 15400 operation), so we don't remove this
frame.
-
We now look at the next frame, which contains the page 42.
This time, page 42 does not appear in the lookahead list of operations,
and so we choose to remove the frame containing page 42.
-
After
doing this, a frame containing page 2 is inserted at the front of the
list and is marked dirty. This makes the final state of the cache be

- Notice that now when the w 15400 and r 2200 operations are performed, the corresponding pages are still in the cache, ie. they will be cache hits. The plain LRU paging algorithm would have removed these pages, causing cache misses.
Pipelined LRU - Example 2
-
This time we will consider an example similar to the previous one.
The only difference is that the value of check_frames is 2,
not 4.
-
The initial state of the cache is again
-
The current and next read/write operations are again:
- w 1492 (page 2)
- w 50 (page 0)
- w 15400 (page 30)
- r 2200 (page 4)
-
So the current operation being performed is a write to address 1492,
which is page 2. Page 2 is not in the cache (ie. a cache miss), so we
need to find a frame to remove.
-
We start with the last frame in the
cache, which contains page 4. However, page 4 appears in the lookahead
list of operations (the r 2200 operation), so we don't remove
this frame.
-
We now look at the next frame,
which contains page 30. Again, page 30 appears in the lookahead list
of operations (the w 15400 operation), so we don't remove this
frame.
-
However, now we have run out of frames to check. This is because the
value of check_frames is 2, and we have already checked 2
frames. So all of the frames which we have checked are required in the
near future by the lookahead list.
-
So now we must choose one of the examined frames to remove, so we will
either remove the frame containing page 4 or the frame containing page
30. According to the spec above, we choose the one which is needed
latest by the lookahead list. So we work from the start of the
lookahead list - first page 0 is needed, then page 30, then page 4. So
page 4 is first needed after page 30, so we remove the frame containing
page 4.
-
After
doing this, a frame containing page 2 is inserted at the front of the
list and is marked dirty. This makes the final state of the cache be

Pipelined LRU - Example 3
-
Consider the following lookahead list of next read/write operations:
- w 1492 (page 2)
- w 50 (page 0)
- w 15400 (page 30)
- w 15300 (page 30)
- w 180 (page 0)
- r 2200 (page 4)
- w 1292 (page 2)
-
Now suppose that the frames were searched and all of the frames were
needed in the near future. In this case, the page which should be
removed is page 4.
-
This is because when you search the lookahead list, you search from the
front of the list to find the first time each page is used. If
you were then to store pages in a list in order of when they were first
found, the list would be: 2, 0, 30, 4. The page to remove is the one
at the end of this list.
- If you instead search from the back of the lookahead list, you will end up choosing to remove the wrong frame.
Submission Information
- Your submission must consist of one or more .cc files, one or more .h files, and a Makefile for creating the program.
- The program must be called pagesim
-
The program will be compiled with the command
make
- Your submission must be placed in a tar file. In order to do this, refer to the submission instructions page.
- Once you have created the tar file you need to submit it, which is also described on the submission instructions page.