
[ Seminars ] [ Seminars on CD ROM ] [ Consulting ]
The basic concept of multiple inheritance (MI)
sounds simple enough.
[[[Notes:
]]]
You
create a new type by inheriting from more than one base class. The syntax is
exactly what you’d expect, and as long as the inheritance diagrams are
simple, MI is simple as well.
However, MI can introduce a number of ambiguities and strange
situations, which are covered in this chapter. But first, it helps to get a
perspective on the
subject.
Before C++, the most successful object-oriented language was
Smalltalk. Smalltalk was created from the ground up as an
OO language. It is often referred to as pure, whereas C++, because it was
built on top of C, is called hybrid. One of the design decisions made
with Smalltalk was that all classes would be derived in a single hierarchy,
rooted in a single base class (called Object – this is the model
for the object-based
hierarchy). You cannot create
a new class in Smalltalk without inheriting it from an existing class, which is
why it takes a certain amount of time to become productive in Smalltalk –
you must learn the class library before you can start making new classes. So the
Smalltalk class hierarchy is always a single monolithic
tree.
Classes in Smalltalk usually have a number of things in
common, and always have some things in common (the characteristics and
behaviors of Object), so you almost never run into a situation where you
need to inherit from more than one base class. However, with C++ you can create
as many hierarchy trees as you want. Therefore, for logical completeness the
language must be able to combine more than one class at a time – thus the
need for multiple inheritance.
However, this was not a crystal-clear case of a feature that
no one could live without, and there was (and still is) a lot of disagreement
about whether MI is really essential in C++. MI was added in AT&T
cfront release 2.0 and was the first significant change to the language.
Since then, a number of other features have been added (notably templates) that
change the way we think about programming and place MI in a much less important
role. You can think of MI as a “minor” language feature that
shouldn’t be involved in your daily design decisions.
One of the most pressing issues that drove MI involved
containers. Suppose you want to create a container that everyone can easily use.
One approach is to use void* as the type inside the container, as with
PStash and Stack. The Smalltalk approach, however, is to make a
container that holds Objects. (Remember that Object is the base
type of the entire Smalltalk hierarchy.) Because everything in Smalltalk is
ultimately derived from Object, any container that holds Objects
can hold anything, so this approach works nicely.
Now consider the situation in C++. Suppose vendor A
creates an object-based hierarchy that includes a useful set of containers
including one you want to use called Holder. Now you come across vendor
B’s class hierarchy that contains some other class that is
important to you, a BitImage class, for example, which holds graphic
images. The only way to make a Holder of BitImages is to inherit a
new class from both Object, so it can be held in the Holder, and
BitImage:
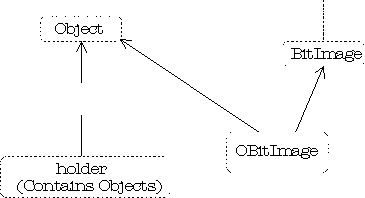
This was seen as an important reason for MI, and a number of
class libraries were built on this model. However, as you saw in Chapter XX, the
addition of templates has changed the way containers are created, so this
situation isn’t a driving issue for MI.
The other reason you may need MI is logical, related to
design. Unlike the above situation, where you don’t have control of the
base classes, in this one you do, and you intentionally use MI to make the
design more flexible or useful. (At least, you may believe this to be the case.)
An example of this is in the original iostream library design:
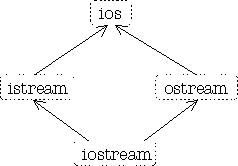
Both istream and ostream are useful classes by
themselves, but they can also be inherited into a class that combines both their
characteristics and behaviors.
Regardless of what motivates you to use MI, a number of
problems arise in the process, and you need to understand them to use
it.
When you inherit from a base class, you get a copy of all the
data members of that base class in your derived class. This copy is referred to
as a subobject. If you multiply inherit from class d1 and class
d2 into class mi, class mi contains one subobject of
d1 and one of d2. So your mi object looks like
this:
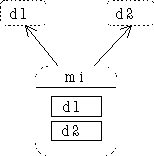
Now consider what happens if d1 and d2 both
inherit from the same base class, called Base:
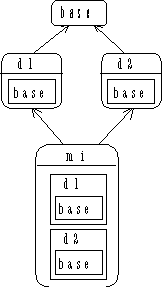
In the above diagram, both d1 and d2 contain a
subobject of Base, so mi contains two subobjects of
Base. Because of the path produced in the diagram, this is sometimes
called a “diamond” in the inheritance hierarchy. Without
diamonds, multiple inheritance is
quite straightforward, but as soon as a diamond appears, trouble starts because
you have duplicate subobjects in your new class. This takes up extra space,
which may or may not be a problem depending on your design. But it also
introduces an
ambiguity.
What happens, in the above diagram, if you want to cast a
pointer to an mi to a pointer to a Base? There are two subobjects
of type Base, so which address does the cast produce? Here’s the
diagram in code:
//: C06:MultipleInheritance1.cpp
// MI & ambiguity
#include "../purge.h"
#include <iostream>
#include <vector>
using namespace std;
class MBase {
public:
virtual char* vf() const = 0;
virtual ~MBase() {}
};
class D1 : public MBase {
public:
char* vf() const { return "D1"; }
};
class D2 : public MBase {
public:
char* vf() const { return "D2"; }
};
// Causes error: ambiguous override of vf():
//! class MI : public D1, public D2 {};
int main() {
vector<MBase*> b;
b.push_back(new D1);
b.push_back(new D2);
// Cannot upcast: which subobject?:
//! b.push_back(new mi);
for(int i = 0; i < b.size(); i++)
cout << b[i]->vf() << endl;
purge(b);
} ///:~Two problems occur here. First, you cannot even create the
class mi because doing so would cause a clash between the two definitions
of vf( ) in D1 and D2.
Second, in the array definition for b[ ] this code
attempts to create a new mi and upcast the address to a MBase*.
The compiler won’t accept this because it has no way of knowing whether
you want to use D1’s subobject MBase or D2’s
subobject MBase for the resulting
address.
To solve the first problem, you must explicitly disambiguate
the function vf( ) by writing a redefinition in the class
mi.
The solution to the second problem is a language extension:
The meaning of the virtual keyword is overloaded. If you inherit a base
class as virtual, only one subobject of that class will ever appear as a
base class. Virtual base classes are implemented by the compiler with pointer
magic in a way suggesting the implementation of ordinary virtual
functions.
Because only one subobject of a virtual base class will ever
appear during multiple inheritance, there is no ambiguity during upcasting.
Here’s an example:
//: C06:MultipleInheritance2.cpp
// Virtual base classes
#include "../purge.h"
#include <iostream>
#include <vector>
using namespace std;
class MBase {
public:
virtual char* vf() const = 0;
virtual ~MBase() {}
};
class D1 : virtual public MBase {
public:
char* vf() const { return "D1"; }
};
class D2 : virtual public MBase {
public:
char* vf() const { return "D2"; }
};
// MUST explicitly disambiguate vf():
class MI : public D1, public D2 {
public:
char* vf() const { return D1::vf();}
};
int main() {
vector<MBase*> b;
b.push_back(new D1);
b.push_back(new D2);
b.push_back(new MI); // OK
for(int i = 0; i < b.size(); i++)
cout << b[i]->vf() << endl;
purge(b);
} ///:~The compiler now accepts the upcast, but notice that you must
still explicitly disambiguate the function vf( ) in MI;
otherwise the compiler wouldn’t know which version to
use.
The use of virtual base classes isn’t quite as simple as
that. The above example uses the (compiler-synthesized) default constructor. If
the virtual base has a constructor, things become a bit strange. To understand
this, you need a new term: most-derived
class.
The most-derived class is the one you’re currently in,
and is particularly important when you’re thinking about constructors. In
the previous example, MBase is the most-derived class inside the
MBase constructor. Inside the D1 constructor, D1 is the
most-derived class, and inside the MI constructor, MI is the
most-derived class.
When you are using a virtual base class, the most-derived
constructor is responsible for initializing that virtual base class. That means
any class, no matter how far away it is from the virtual base, is responsible
for initializing it. Here’s an example:
//: C06:MultipleInheritance3.cpp
// Virtual base initialization
// Virtual base classes must always be
// Initialized by the "most-derived" class
#include "../purge.h"
#include <iostream>
#include <vector>
using namespace std;
class MBase {
public:
MBase(int) {}
virtual char* vf() const = 0;
virtual ~MBase() {}
};
class D1 : virtual public MBase {
public:
D1() : MBase(1) {}
char* vf() const { return "D1"; }
};
class D2 : virtual public MBase {
public:
D2() : MBase(2) {}
char* vf() const { return "D2"; }
};
class MI : public D1, public D2 {
public:
MI() : MBase(3) {}
char* vf() const {
return D1::vf(); // MUST disambiguate
}
};
class X : public MI {
public:
// You must ALWAYS init the virtual base:
X() : MBase(4) {}
};
int main() {
vector<MBase*> b;
b.push_back(new D1);
b.push_back(new D2);
b.push_back(new MI); // OK
b.push_back(new X);
for(int i = 0; i < b.size(); i++)
cout << b[i]->vf() << endl;
purge(b);
} ///:~As you would expect, both D1 and D2 must
initialize MBase in their constructor. But so must MI and
X, even though they are more than one layer away! That’s because
each one in turn becomes the most-derived class. The compiler can’t know
whether to use D1’s initialization of MBase or to use
D2’s version. Thus you are always forced to do it in the
most-derived class. Note that only the single selected virtual base constructor
is called.
Forcing the most-derived class to initialize a virtual base
that may be buried deep in the class hierarchy can seem like a tedious and
confusing task to put upon the user of your class. It’s better to make
this invisible, which is done by creating a default constructor for the virtual
base class, like this:
//: C06:MultipleInheritance4.cpp
// "Tying off" virtual bases
// so you don't have to worry about them
// in derived classes
#include "../purge.h"
#include <iostream>
#include <vector>
using namespace std;
class MBase {
public:
// Default constructor removes responsibility:
MBase(int = 0) {}
virtual char* vf() const = 0;
virtual ~MBase() {}
};
class D1 : virtual public MBase {
public:
D1() : MBase(1) {}
char* vf() const { return "D1"; }
};
class D2 : virtual public MBase {
public:
D2() : MBase(2) {}
char* vf() const { return "D2"; }
};
class MI : public D1, public D2 {
public:
MI() {} // Calls default constructor for MBase
char* vf() const {
return D1::vf(); // MUST disambiguate
}
};
class X : public MI {
public:
X() {} // Calls default constructor for MBase
};
int main() {
vector<MBase*> b;
b.push_back(new D1);
b.push_back(new D2);
b.push_back(new MI); // OK
b.push_back(new X);
for(int i = 0; i < b.size(); i++)
cout << b[i]->vf() << endl;
purge(b);
} ///:~If you can always arrange for a virtual base class to have a
default constructor, you’ll make things much easier for anyone who
inherits from that
class.
The term “pointer magic” has been used to describe
the way virtual inheritance is implemented. You can see the physical overhead of
virtual inheritance with the following program:
//: C06:Overhead.cpp
// Virtual base class overhead
#include <fstream>
using namespace std;
ofstream out("overhead.out");
class MBase {
public:
virtual void f() const {};
virtual ~MBase() {}
};
class NonVirtualInheritance
: public MBase {};
class VirtualInheritance
: virtual public MBase {};
class VirtualInheritance2
: virtual public MBase {};
class MI
: public VirtualInheritance,
public VirtualInheritance2 {};
#define WRITE(ARG) \
out << #ARG << " = " << ARG << endl;
int main() {
MBase b;
WRITE(sizeof(b));
NonVirtualInheritance nonv_inheritance;
WRITE(sizeof(nonv_inheritance));
VirtualInheritance v_inheritance;
WRITE(sizeof(v_inheritance));
MI mi;
WRITE(sizeof(mi));
} ///:~Each of these classes only contains a single byte, and the
“core size” is that byte. Because all these classes contain virtual
functions, you expect the object size to be bigger than the core size by a
pointer (at least – your compiler may also pad extra bytes into an object
for alignment). The results are a bit surprising (these are from one particular
compiler; yours may do it differently):
sizeof(b) = 2 sizeof(nonv_inheritance) = 2 sizeof(v_inheritance) = 6 sizeof(MI) = 12
Both b and nonv_inheritance
contain the extra pointer, as expected. But when virtual inheritance is added,
it would appear that the VPTR plus two extra pointers are added! By the
time the multiple inheritance is performed, the object appears to contain five
extra pointers (however, one of these is probably a second VPTR for the second
multiply inherited subobject).
The curious can certainly probe into your particular
implementation and look at the assembly language for member selection to
determine exactly what these extra bytes are for, and the cost of member
selection with multiple
inheritance[20]. The
rest of you have probably seen enough to guess that quite a bit more goes on
with virtual multiple inheritance, so it should be used sparingly (or avoided)
when efficiency is an
issue.
When you embed subobjects of a class inside a new class,
whether you do it by creating member objects or through inheritance, each
subobject is placed within the new object by the compiler. Of course, each
subobject has its own this pointer, and as long as you’re dealing
with member objects, everything is quite straightforward. But as soon as
multiple inheritance is introduced, a funny thing occurs: An object can have
more than one this pointer because the object represents more than one
type during upcasting. The following example demonstrates this point:
//: C06:Mithis.cpp
// MI and the "this" pointer
#include <fstream>
using namespace std;
ofstream out("mithis.out");
class Base1 {
char c[0x10];
public:
void printthis1() {
out << "Base1 this = " << this << endl;
}
};
class Base2 {
char c[0x10];
public:
void printthis2() {
out << "Base2 this = " << this << endl;
}
};
class Member1 {
char c[0x10];
public:
void printthism1() {
out << "Member1 this = " << this << endl;
}
};
class Member2 {
char c[0x10];
public:
void printthism2() {
out << "Member2 this = " << this << endl;
}
};
class MI : public Base1, public Base2 {
Member1 m1;
Member2 m2;
public:
void printthis() {
out << "MI this = " << this << endl;
printthis1();
printthis2();
m1.printthism1();
m2.printthism2();
}
};
int main() {
MI mi;
out << "sizeof(mi) = "
<< hex << sizeof(mi) << " hex" << endl;
mi.printthis();
// A second demonstration:
Base1* b1 = &mi; // Upcast
Base2* b2 = &mi; // Upcast
out << "Base 1 pointer = " << b1 << endl;
out << "Base 2 pointer = " << b2 << endl;
} ///:~The arrays of bytes inside each class are created with
hexadecimal sizes, so the output addresses (which are printed in hex) are easy
to read. Each class has a function that prints its this pointer, and
these classes are assembled with both multiple inheritance and composition into
the class MI, which prints its own address and the addresses of all the
other subobjects. This function is called in main( ). You can
clearly see that you get two different this pointers for the same object.
The address of the MI object is taken and upcast to the two different
types. Here’s the output:[21]
sizeof(mi) = 40 hex mi this = 0x223e Base1 this = 0x223e Base2 this = 0x224e Member1 this = 0x225e Member2 this = 0x226e Base 1 pointer = 0x223e Base 2 pointer = 0x224e
Although object layouts vary from compiler to compiler and are
not specified in Standard C++, this one is fairly typical. The starting address
of the object corresponds to the address of the first class in the base-class
list. Then the second inherited class is placed, followed by the member objects
in order of declaration.
When the upcast to the Base1 and Base2 pointers
occur, you can see that, even though they’re ostensibly pointing to the
same object, they must actually have different this pointers, so the
proper starting address can be passed to the member functions of each subobject.
The only way things can work correctly is if this implicit upcasting takes place
when you call a member function for a multiply inherited
subobject.
Normally this isn’t a problem, because you want to call
member functions that are concerned with that subobject of the multiply
inherited object. However, if your member function needs to know the true
starting address of the object, multiple inheritance causes problems.
Ironically, this happens in one of the situations where multiple inheritance
seems to be useful: persistence.
The lifetime of a local object is the scope in which it is
defined. The lifetime of a global object is the lifetime of the program. A
persistent object lives between invocations of a
program: You can normally think of it as existing on disk instead of in memory.
One definition of an object-oriented
database is “a collection of
persistent objects.”
To implement persistence, you must move a persistent object
from disk into memory in order to call functions for it, and later store it to
disk before the program expires. Four issues arise when storing an object on
disk:
Because
the object must be converted back and forth between a layout in memory and a
serial representation on disk, the process is called serialization
(to write an object to disk) and deserialization
(to restore an object from disk). Although it would be
very convenient, these processes require too much overhead to support directly
in the language. Class libraries will often build in support for serialization
and deserialization by adding special member functions and placing requirements
on new classes. (Usually some sort of serialize( ) function must be
written for each new class.) Also, persistence is generally not automatic; you
must usually explicitly write and read the objects.
Consider sidestepping the pointer issues for now and creating
a class that installs persistence into simple objects using multiple
inheritance. By inheriting the persistence class along with your new
class, you automatically create classes that can be read from and written to
disk. Although this sounds great, the use of multiple inheritance introduces a
pitfall, as seen in the following example.
//: C06:Persist1.cpp
// Simple persistence with MI
#include "../require.h"
#include <iostream>
#include <fstream>
using namespace std;
class Persistent {
int objSize; // Size of stored object
public:
Persistent(int sz) : objSize(sz) {}
void write(ostream& out) const {
out.write((char*)this, objSize);
}
void read(istream& in) {
in.read((char*)this, objSize);
}
};
class Data {
float f[3];
public:
Data(float f0 = 0.0, float f1 = 0.0,
float f2 = 0.0) {
f[0] = f0;
f[1] = f1;
f[2] = f2;
}
void print(const char* msg = "") const {
if(*msg) cout << msg << " ";
for(int i = 0; i < 3; i++)
cout << "f[" << i << "] = "
<< f[i] << endl;
}
};
class WData1 : public Persistent, public Data {
public:
WData1(float f0 = 0.0, float f1 = 0.0,
float f2 = 0.0) : Data(f0, f1, f2),
Persistent(sizeof(WData1)) {}
};
class WData2 : public Data, public Persistent {
public:
WData2(float f0 = 0.0, float f1 = 0.0,
float f2 = 0.0) : Data(f0, f1, f2),
Persistent(sizeof(WData2)) {}
};
int main() {
{
ofstream f1("f1.dat"), f2("f2.dat");
assure(f1, "f1.dat"); assure(f2, "f2.dat");
WData1 d1(1.1, 2.2, 3.3);
WData2 d2(4.4, 5.5, 6.6);
d1.print("d1 before storage");
d2.print("d2 before storage");
d1.write(f1);
d2.write(f2);
} // Closes files
ifstream f1("f1.dat"), f2("f2.dat");
assure(f1, "f1.dat"); assure(f2, "f2.dat");
WData1 d1;
WData2 d2;
d1.read(f1);
d2.read(f2);
d1.print("d1 after storage");
d2.print("d2 after storage");
} ///:~In this very simple version, the
Persistent::read( ) and Persistent::write( ) functions
take the this pointer and call iostream read( ) and
write( )
functions.
(Note that any type of iostream can be used). A more sophisticated
Persistent class would call a virtual write( )
function for each subobject.
With the language features covered so far in the book, the
number of bytes in the object cannot be known by the Persistent class so
it is inserted as a constructor argument. (In Chapter XX, run-time type
identification shows how you can find the exact type of an object given only
a base pointer; once you have the exact type you can find out the correct size
with the sizeof operator.)
The Data class contains no pointers or
VPTR, so there is no danger in simply writing it to disk
and reading it back again. And it works fine in class WData1 when, in
main( ), it’s written to file F1.DAT and later read back
again. However, when Persistent is second in the inheritance list of
WData2, the this pointer for Persistent is offset to the
end of the object, so it reads and writes past the end of the object. This not
only produces garbage when reading the object from the file, it’s
dangerous because it walks over any storage that occurs after the
object.
This problem occurs in multiple
inheritance any time a class must
produce the this pointer for the actual object from a subobject’s
this pointer. Of course, if you know your compiler always lays out
objects in order of declaration in the inheritance list, you can ensure that you
always put the critical class at the beginning of the list (assuming
there’s only one critical class). However, such a class may exist in the
inheritance hierarchy of another class and you may unwittingly put it in the
wrong place during multiple inheritance. Fortunately, using run-time type
identification (the subject of Chapter XX) will produce
the proper pointer to the actual object, even if multiple inheritance is
used.
A more practical approach to persistence, and one you will see
employed more often, is to create virtual functions in the base class for
reading and writing and then require the creator of any new class that must be
streamed to redefine these functions. The argument to the function is the stream
object to write to or read from.[22] Then the
creator of the class, who knows best how the new parts should be read or
written, is responsible for making the correct function calls. This
doesn’t have the “magical” quality of the previous example,
and it requires more coding and knowledge on the part of the user, but it works
and doesn’t break when pointers are present:
//: C06:Persist2.cpp
// Improved MI persistence
#include "../require.h"
#include <iostream>
#include <fstream>
#include <cstring>
using namespace std;
class Persistent {
public:
virtual void write(ostream& out) const = 0;
virtual void read(istream& in) = 0;
virtual ~Persistent() {}
};
class Data {
protected:
float f[3];
public:
Data(float f0 = 0.0, float f1 = 0.0,
float f2 = 0.0) {
f[0] = f0;
f[1] = f1;
f[2] = f2;
}
void print(const char* msg = "") const {
if(*msg) cout << msg << endl;
for(int i = 0; i < 3; i++)
cout << "f[" << i << "] = "
<< f[i] << endl;
}
};
class WData1 : public Persistent, public Data {
public:
WData1(float f0 = 0.0, float f1 = 0.0,
float f2 = 0.0) : Data(f0, f1, f2) {}
void write(ostream& out) const {
out << f[0] << " "
<< f[1] << " " << f[2] << " ";
}
void read(istream& in) {
in >> f[0] >> f[1] >> f[2];
}
};
class WData2 : public Data, public Persistent {
public:
WData2(float f0 = 0.0, float f1 = 0.0,
float f2 = 0.0) : Data(f0, f1, f2) {}
void write(ostream& out) const {
out << f[0] << " "
<< f[1] << " " << f[2] << " ";
}
void read(istream& in) {
in >> f[0] >> f[1] >> f[2];
}
};
class Conglomerate : public Data,
public Persistent {
char* name; // Contains a pointer
WData1 d1;
WData2 d2;
public:
Conglomerate(const char* nm = "",
float f0 = 0.0, float f1 = 0.0,
float f2 = 0.0, float f3 = 0.0,
float f4 = 0.0, float f5 = 0.0,
float f6 = 0.0, float f7 = 0.0,
float f8= 0.0) : Data(f0, f1, f2),
d1(f3, f4, f5), d2(f6, f7, f8) {
name = new char[strlen(nm) + 1];
strcpy(name, nm);
}
void write(ostream& out) const {
int i = strlen(name) + 1;
out << i << " "; // Store size of string
out << name << endl;
d1.write(out);
d2.write(out);
out << f[0] << " " << f[1] << " " << f[2];
}
// Must read in same order as write:
void read(istream& in) {
delete []name; // Remove old storage
int i;
in >> i >> ws; // Get int, strip whitespace
name = new char[i];
in.getline(name, i);
d1.read(in);
d2.read(in);
in >> f[0] >> f[1] >> f[2];
}
void print() const {
Data::print(name);
d1.print();
d2.print();
}
};
int main() {
{
ofstream data("data.dat");
assure(data, "data.dat");
Conglomerate C("This is Conglomerate C",
1.1, 2.2, 3.3, 4.4, 5.5,
6.6, 7.7, 8.8, 9.9);
cout << "C before storage" << endl;
C.print();
C.write(data);
} // Closes file
ifstream data("data.dat");
assure(data, "data.dat");
Conglomerate C;
C.read(data);
cout << "after storage: " << endl;
C.print();
} ///:~The pure virtual functions in Persistent must be
redefined in the derived classes to perform the proper reading and writing. If
you already knew that Data would be persistent, you could inherit
directly from Persistent and redefine the functions there, thus
eliminating the need for multiple inheritance. This example is based on the idea
that you don’t own the code for Data, that it was created elsewhere
and may be part of another class hierarchy so you don’t have control over
its inheritance. However, for this scheme to work correctly you must have access
to the underlying implementation so it can be stored; thus the use of
protected.
The classes WData1 and WData2 use familiar
iostream inserters and extractors to store and retrieve the protected
data in Data to and from the iostream object. In write( ),
you can see that spaces are added after each floating point number is written;
these are necessary to allow parsing of the data on input.
The class Conglomerate not only inherits from
Data, it also has member objects of type WData1 and WData2,
as well as a pointer to a character string. In addition, all the classes that
inherit from Persistent also contain a VPTR, so this example shows the
kind of problem you’ll actually encounter when using
persistence.
When you create write( ) and read( )
function pairs, the read( ) must exactly mirror what happens during
the write( ), so read( ) pulls the bits off the disk the
same way they were placed there by write( ). Here, the first problem
that’s tackled is the char*, which points to a string of any
length. The size of the string is calculated and stored on disk as an int
(followed by a space to enable parsing) to allow the read( )
function to allocate the correct amount of storage.
When you have subobjects that have read( ) and
write( ) member functions, all you need to do is call those
functions in the new read( ) and write( ) functions.
This is followed by direct storage of the members in the base class.
People have gone to great lengths to automate persistence, for
example, by creating modified preprocessors to support a
“persistent” keyword to be applied when defining a class. One can
imagine a more elegant approach than the one shown here for implementing
persistence, but it has the advantage that it works under all implementations of
C++, doesn’t require special language extensions, and is relatively
bulletproof.
The need for multiple inheritance in
Persist2.cpp is contrived, based on the concept that you don’t have
control of some of the code in the project. Upon examination of the example, you
can see that MI can be easily avoided by using member objects of type
Data, and putting the virtual read( )and write( )
members inside Data or WData1 and WData2 rather than in a
separate class. There are many situations like this one where multiple
inheritance may be avoided; the language feature is included for unusual,
special-case situations that would otherwise be difficult or impossible to
handle. But when the question of whether to use multiple inheritance comes up,
you should ask two questions:
If you can’t answer “no” to both
questions, you can avoid using MI and should probably do so.
One situation to watch for is when one class only needs to be
upcast as a function argument. In that case, the class can be embedded and an
automatic type conversion operator provided in your new class to produce a
reference to the embedded object. Any time you use an object of your new class
as an argument to a function that expects the embedded object, the type
conversion operator is used. However, type conversion can’t be used for
normal member selection; that requires
inheritance.
Rodents & pets(play)
interfaces in general
One of the best arguments for multiple inheritance involves
code that’s out of your control. Suppose you’ve acquired a library
that consists of a header file and compiled member functions, but no source code
for member functions. This library is a class hierarchy with virtual functions,
and it contains some global functions that take pointers to the base class of
the library; that is, it uses the library objects polymorphically. Now suppose
you build an application around this library, and write your own code that uses
the base class polymorphically.
Later in the development of the project or sometime during its
maintenance, you discover that the base-class interface provided by the vendor
is incomplete: A function may be nonvirtual and you need it to be virtual, or a
virtual function is completely missing in the interface, but essential to the
solution of your problem. If you had the source code, you could go back and put
it in. But you don’t, and you have a lot of existing code that depends on
the original interface. Here, multiple inheritance is the perfect
solution.
For example, here’s the header file for a library you
acquire:
//: C06:Vendor.h
// Vendor-supplied class header
// You only get this & the compiled Vendor.obj
#ifndef VENDOR_H
#define VENDOR_H
class Vendor {
public:
virtual void v() const;
void f() const;
~Vendor();
};
class Vendor1 : public Vendor {
public:
void v() const;
void f() const;
~Vendor1();
};
void A(const Vendor&);
void B(const Vendor&);
// Etc.
#endif // VENDOR_H ///:~Assume the library is much bigger, with more derived classes
and a larger interface. Notice that it also includes the functions
A( ) and B( ), which take a base pointer and treat it
polymorphically. Here’s the implementation file for the library:
//: C06:Vendor.cpp {O}
// Implementation of VENDOR.H
// This is compiled and unavailable to you
#include "Vendor.h"
#include <fstream>
using namespace std;
extern ofstream out; // For trace info
void Vendor::v() const {
out << "Vendor::v()\n";
}
void Vendor::f() const {
out << "Vendor::f()\n";
}
Vendor::~Vendor() {
out << "~Vendor()\n";
}
void Vendor1::v() const {
out << "Vendor1::v()\n";
}
void Vendor1::f() const {
out << "Vendor1::f()\n";
}
Vendor1::~Vendor1() {
out << "~Vendor1()\n";
}
void A(const Vendor& V) {
// ...
V.v();
V.f();
//..
}
void B(const Vendor& V) {
// ...
V.v();
V.f();
//..
} ///:~In your project, this source code is unavailable to you.
Instead, you get a compiled file as Vendor.obj or Vendor.lib (or
the equivalent for your system).
The problem occurs in the use of this library. First, the
destructor isn’t virtual. This is actually a design error on the part of
the library creator. In addition, f( ) was not made virtual; assume
the library creator decided it wouldn’t need to be. And you discover that
the interface to the base class is missing a function essential to the solution
of your problem. Also suppose you’ve already written a fair amount of code
using the existing interface (not to mention the functions A( ) and
B( ), which are out of your control), and you don’t want to
change it.
To repair the problem, create your own class interface and
multiply inherit a new set of derived classes from your interface and from the
existing classes:
//: C06:Paste.cpp
//{L} Vendor
// Fixing a mess with MI
#include "Vendor.h"
#include <fstream>
using namespace std;
ofstream out("paste.out");
class MyBase { // Repair Vendor interface
public:
virtual void v() const = 0;
virtual void f() const = 0;
// New interface function:
virtual void g() const = 0;
virtual ~MyBase() { out << "~MyBase()\n"; }
};
class Paste1 : public MyBase, public Vendor1 {
public:
void v() const {
out << "Paste1::v()\n";
Vendor1::v();
}
void f() const {
out << "Paste1::f()\n";
Vendor1::f();
}
void g() const {
out << "Paste1::g()\n";
}
~Paste1() { out << "~Paste1()\n"; }
};
int main() {
Paste1& p1p = *new Paste1;
MyBase& mp = p1p; // Upcast
out << "calling f()\n";
mp.f(); // Right behavior
out << "calling g()\n";
mp.g(); // New behavior
out << "calling A(p1p)\n";
A(p1p); // Same old behavior
out << "calling B(p1p)\n";
B(p1p); // Same old behavior
out << "delete mp\n";
// Deleting a reference to a heap object:
delete ∓ // Right behavior
} ///:~In MyBase (which does not use MI), both
f( ) and the destructor are now virtual, and a new virtual function
g( ) has been added to the interface. Now each of the derived
classes in the original library must be recreated, mixing in the new interface
with MI. The functions Paste1::v( ) and Paste1::f( )need
to call only the original base-class versions of their functions. But now, if
you upcast to MyBase as in main( )
MyBase* mp = p1p; // Upcast
any function calls made
through mp will be polymorphic, including delete. Also, the new
interface function g( ) can be called through mp.
Here’s the output of the program:
calling f() Paste1::f() Vendor1::f() calling g() Paste1::g() calling A(p1p) Paste1::v() Vendor1::v() Vendor::f() calling B(p1p) Paste1::v() Vendor1::v() Vendor::f() delete mp ~Paste1() ~Vendor1() ~Vendor() ~MyBase()
The original library functions A( ) and
B( ) still work the same (assuming the new v( ) calls
its base-class version). The destructor is now virtual and exhibits the correct
behavior.
Although this is a messy example, it does occur in practice
and it’s a good demonstration of where multiple inheritance is clearly
necessary: You must be able to upcast to both base
classes.
The reason MI exists in C++ and not in other OOP languages is
that C++ is a hybrid language and couldn’t enforce a single monolithic
class hierarchy the way Smalltalk does. Instead, C++ allows many inheritance
trees to be formed, so sometimes you may need to combine the interfaces from two
or more trees into a new class.
If no “diamonds” appear in your class hierarchy,
MI is fairly simple (although identical function signatures in base classes must
be resolved). If a diamond appears, then you must deal with the problems of
duplicate subobjects by introducing virtual base classes. This not only adds
confusion, but the underlying representation becomes more complex and less
efficient.
Multiple inheritance has been called the “goto of the
90’s”.[23]
This seems appropriate because, like a goto, MI is best avoided in normal
programming, but can occasionally be very useful. It’s a
“minor” but more advanced feature of C++, designed to solve problems
that arise in special situations. If you find yourself using it often, you may
want to take a look at your reasoning. A good Occam’s Razor is to ask,
“Must I upcast to all of the base classes?” If not, your life will
be easier if you embed instances of all the classes you don’t need
to upcast to.
[20] See also
Jan Gray, “C++ Under the Hood”, a chapter in Black Belt
C++ (edited by Bruce Eckel, M&T Press, 1995).
[21] For easy
readability the code was generated for a small-model Intel
processor.
[22] Sometimes
there’s only a single function for streaming, and the argument contains
information about whether you’re reading or writing.
[23] A phrase
coined by Zack Urlocker.